
Introduction
I found myself wondering what Unicode symbols looked like at the bit level. In the ASCII world, a single byte is a single character, so the encoding is relatively straightforward. However, in the UTF-8 encoding, a single character can span multiple bytes, so how does the program know when the character starts and ends?
This question led me on a winding trail of history via Wikipedia and other sources through UTF-8, UTF-16 back to ASCII. I thought I knew ASCII well, but found myself wondering, why is it laid out like this? It turns out it is the way it is largely due to Teletype systems which are the way they are because of telegraphic typewriters which are finally based on the telegraph and therefore Morse code. This seemed like a reasonable place to bottom out. In this post, I’ll walk through the different pieces of the story that led us from − − − • • • to 😊.
1825 - Samuel Morse
Our story begins in 1825 with Samuel Morse. Morse was 33 years old and married to a woman named Lucretia. Together, they had 3 children, the youngest of whom had just recently been born. Morse was a renowned painter and was commissioned to paint a portrait of the revolutionary war hero Marquis de Lafayette (age 68 at the time). Morse went to D.C. to paint the portrait.
Morse’s portrait of Lafayette
In the midst of his painting, he received a letter from his father saying that his wife had been sick, but was recovering. The next day, he received another letter stating that she had passed suddenly. By the time he got back to New York, she had already been buried. Morse was heartbroken and frustrated that his wife was suffering for days without his knowledge. This set his mind toward improving the speed of communication.
1836 - Morse Code
Fast forward 10 years to 1836, and Morse has made friends with Joseph Henry and Alfred Vail. Together, they develop the first electrical telegraph system. Morse came up with an early version of the code we know today, except he wanted the code to only transmit numerals. The telegraph operators would then look up the numerals in a code book to see which characters they corresponded to. Alfred Vail convinced him to include letters. In order to determine which letters were most common and therefore should have the shortest encoding to be easiest to transmit, Vail went to his local newspaper and counted the letters in their movable type system.
![Table of Morse Code][morse-table]
1870 - Baudot Code
The next character encoding came from Émile Baudot. Baudot realized that the typical telegraph line was idle most of the time when transmitting a message. He wanted a way to increase the efficiency, so he developed a system of time multiplexing. Each of 5 different messages could be sent simultaneously across the same wire by splitting up their characters and interleaving their transmission. This interleaving or multiplexing (and subsequent de-multiplexing) was achieved through a system of synchronized clockwork devices.
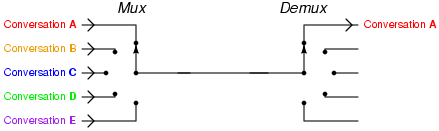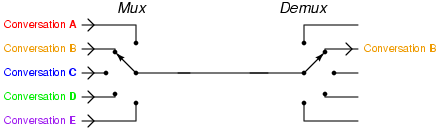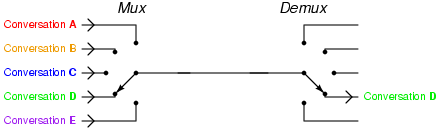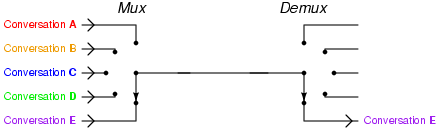
Photo credit Tony R. Kuphaldt 2006

A Baudot keyboard
In order for his system to work, each character needed to be transmittable in precisely same time interval. To achieve this, he developed a 5 bit encoding with a corresponding 5 bit keyboard. The keyboard had 3 keys for the right hand and 2 keys for the left. Baudot designed his code in the interests of making it easy for the operator to remember and easy to input into the machine.
A 5 bit encoding only has 2^5 or 32 available options. Accounting for 26 characters in the Roman alphabet left 6 slots for other characters (5 after leaving a single character “blank”). This was not enough to even encode the numerals 0-9, so Baudot included 2 toggle characters. The first, called “Figure”, would cause all subsequent characters to be interpreted as symbols. The second called “Letter” would switch back to “letter” mode. If either toggle was observed while already in a particular mode, it would a no-op blank character.
Baudot’s code became known as International Telegraph Alphabet No. 1 (ITA-1).
1901 - Murray-Baudot Code
In 1901, typewriters were becoming more popular and with it, typing training was becoming more common. Donald Murray made the observation that if a typewriter could be made to send telegraphs, then all these people trained in typing could also be telegraph operators. He designed a keyboard that mimicked the typical typewriter interface.

A murr keyboard
In Murray’s system, the operator would press a key corresponding to the letter they wanted to transmit, and the machine would handle translating it into the appropriate bits. Since the operator no longer needed to enter the code, Murray made some modifications to Baudot’s code to make the most common letters contain the fewest “on” bits. This was because each “on” bit required a mechanical operation in the machine, and fewer mechanical operations meant the machine would last longer. Murray’s modifications also added “control” characters like “carriage return” and “line feed” which we still see in encodings today.
In 1924, the Murray-Baudot code was standardized by the ITU (International Telegraph Union) into ITA-2.
1963 - ASCII
Why 7 bits?
With the rise of digital devices, the need for a new encoding arose. ITA-2 and other encodings at the time had the 26 alphabetic characters, 10 numerals and ranged from 11 to 25 special graphic symbols. To incorporate all of these plus newly added control characters to support new types of devices, the code needed to support more than the 64 bits allowed by a 6 bit encoding, which led to the decision of 7 bits. A shift function similar to that in the Baudot code was considered, but the loss in reliability for data transmission was deemed to high.
At this point, the entry devices being used were electronic, and not mechanical, so encoding for the fewest “On” bits like Murray did was unnecessary. This freed up the spec to prioritize ease of “sorting” by making the encoding alphabetical (that is letters earlier in the alphabet have lower numbers in the encoding). All in all there were 95 printable characters and 33 non-printing control characters (See the wikipedia article on control characters for a list of these).
Upper and Lower Case
There was a debate over whether to include lower case letters in the ASCII spec at all. Not all devices even supported printing lower case letters, and those code positions could have been reserved for more control characters. They eventually decided it was worth it and the compromise was that lower case letters would come later and would be the same as their upper case counterparts aside from the high bit. This made it easy to handle case insensitive typing (just ignore the highest bit).
Other Interesting Ordering Selections
The digits 0-9 have 011 as their top 3 bits, but the bottom 4 bits are their binary value. This makes it easy to transcode a binary number into ASCII. Control characters are grouped together, as are many “symbols” (with the exception of those coming in between upper and lowercase letters). Additionally, the symbols corresponding to the “shift” above the numerals differ only by 1 bit. For instance, the numeral 1 has low bits “0001” (as discussed earlier), and high bits “011”. The “!” character also has low bits “0001”, but it has high bits “010”. Thus, a keyboard need only flip one bit to enact the “shift” key.
1991 Latin Alphabets and Unicode
ASCII was sufficient for communicating in modern English, but other languages using the Latin alphabet with additional symbols were out of luck. Computers started shifted towards 8-bit bytes, so often ASCII characters had an unused high bit. To support these additional symbols, several encodings were developed which used ASCII for 0-127, and a separate encoding for 128-255. Since this was not enough code positions to handle all the symbols for all the languages, several different encodings were developed (i.e. Latin-1 through Latin-10 and others.)
These separate encodings allowed for many languages to be more correctly represented, however, they disallowed multiple languages from occurring in the same file. For instance, if you wanted an “Õ” to occur in the same file as a “Ф”, you were out of luck.
In 1991, Joe Becker, Lee Collins, and Mark Davis with the help of some others outlined a “unique, unified, universal encoding”. The idea was to have a single encoding that could handle all of the various symbols so you could have multiple in the same file and you wouldn’t have to worry about supporting 10’s of different encodings in your application. They originally devised it to be a 16 bit encoding under the assumption that that would be enough (65,536 code positions).
1992 UTF-8 and UTF-16
Several different encodings for unicode were developed. The goals of the encodings were to have compatibility with ASCII so an ASCII file would not need to be modified in order to be read as Unicode.
UTF-16 uses 1 or 2 8-bit bytes. It sacrifices a range of numbers in order to encode some code points as 2 bytes rather than one. For the 2 byte characters, it subtracts a number from it to get a 20 bit number, it then splits those 20 bits between 2 bytes and adds a particular number to it. This means there is a range of values that are reserved for UTF-16.
UTF-8 is a variable-length encoding with 8 bit units. It was developed in by Ken Thompson and Rob Pike. For ASCII characters, all the bits are the same. For a unicode code point, there is first a “header” character followed by “continuation” bytes. The header character has between 2 and 4 high bits set to 1 followed by a 0. The number of 1’s corresponds to the total length of the code point in bytes. The continuation byte has a leading “10” in the highest order bits. The bits other than the ones used for the header/continuation information are used to encode the “code point” number for the character. I recommend the table on Wikipedia which color codes header, continuation and code point bits.
There are several nice things about this format. First, the header information tells you the length of the character, so you are not dependent on reading a subsequent byte to tell you the character is over. Second, picking up a string of bytes midway through means you will lose a maximum of 1 character (In the worst case, you pick up a continuation byte, and you just discard it until you get the next “header” byte or an ASCII byte.)
Originally, UTF8 characters supported up to 6 bytes, and 2 billion valid code points (Although there are 48 possible bits, only 31 are available for encoding separate code points since the other 16 are used for header/continuation). This was limited to 4 bytes in order to have compatibility with UTF-16. In addition to limiting to 4 bytes, several code points in the lower ranges were deemed invalid since they would interfere with the UTF-16 surrogate pairs.
As of this writing, UTF-8 is used by 88.7% of all websites according to w3techs.com.
Further Reading
- Best of Interface Age Volume 2: General Purpose Software (PDF) - This has an article called “Inside ASCII” with some interesting insights into the decisions that went into the ASCII encoding.
- History of the ITU
- Baudot Code expressed like the cover of the Coldplay Album X&Y
- An annotated history of some character codes or ASCII: American Standard Code for Information Infiltration